Data Mirroring
데이터 미러링이란?
데이터 미러링이란 데이터베이스, 스토리지, 메시지 큐, 캐시 등 데이터를 다루는 시스템의 내용을 실시간으로 동기화하여 두 개 이상의 시스템에서 동일한 상태를 유지하는 프로세스에요. 일반적으로 시스템 장애에 따른 데이터 손실에 대비하거나, 데이터 분석 등을 위해 사용되는 기술로 Felice 에서는 데이터 미러링 서비스를 통해 고객이 별도의 인프라 구축 없이도 데이터 이중화를 손쉽게 구현할 수 있도록 지원하고 있어요.
데이터 미러링은 다음과 같은 상황에서 유용하게 사용될 수 있어요.
1. 재해 복구 (Disaster Recovery) : 사용 중이던 Kafka 클러스터에 데이터 손실 또는 시스템 장애가 발생할 수 있어요. 이런 경우, 데이터 미러링을 통해 복제된 백업 클러스터를 통해 신속하게 시스템을 복구할 수 있어요. 만약, 하나의 클러스터가 장애를 겪으면, 복제된 클러스터로 즉시 대체하여 서비스 중단을 최소화할 수도 있어요.
2. 데이터 분석 : 지리적으로 먼 곳에 위치한 클러스터의 데이터들을 중앙 클러스터로 복제하여, 다양한 데이터 소스를 통합하여 분석할 수 있어요. 이를 통해, 전체 비즈니스에 대한 종합 데이터를 확보하여 실시간으로 분석할 수 있으며, 이를 통해 비즈니스 인사이트를 도출할 수 있어요.
데이터 미러링 주요 개념
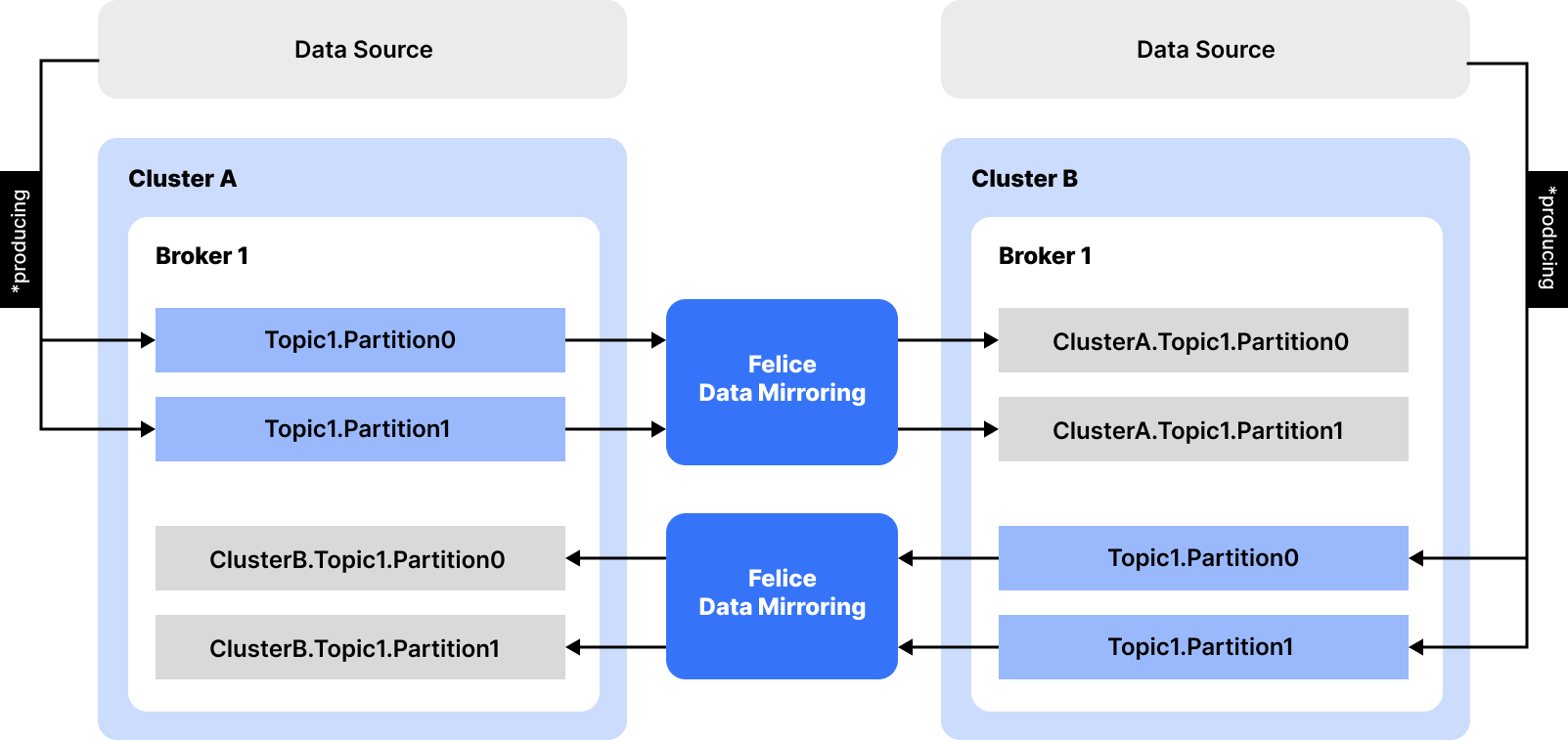
데이터 미러링 작업 (Mirroring Job)
데이터 미러링의 작업 단위에요. 해당 작업이 실행되는 Kafka Connect 클러스터, 소스 클러스터 및 타겟 클러스터, 작업 구성요소 등과 같은 정보가 하나의 작업 단위로 묶여서 관리돼요.
데이터 미러링 서비스는 Kafka Connect 프레임워크를 기반으로 동작하는 여러 MirrorMaker 커넥터들로 구성되어 있어요. 따라서 데이터 미러링 서비스를 사용하기 위해서는 Kafka Connect에 대한 이해가 필요해요. 소스 클러스터에서 타겟 클러스터로 데이터를 복제하는 과정은 Kafka Connect의 다양한 기능을 활용하여 수행되며, 이때 MirrorSourceConnector와 MirrorCheckpointConnector와 같은 전용 커넥터들이 데이터 미러링을 위한 핵심 구성요소로 사용되고 있기 때문이에요.
Kafka Connect 에 대한 더 자세한 내용은 Kafka Connect 문서를 참고해주세요.
소스 클러스터 (Source Cluster), 타겟 클러스터 (Target Cluster)
- 소스 클러스터 : 데이터 미러링 작업에서 데이터를 제공하는 원본 Kafka 클러스터를 뜻해요.
- 타겟 클러스터 : 데이터 미러링 작업에서 복제된 데이터를 받는 목적지 Kafka 클러스터를 뜻해요.
데이터 미러링 작업에서는 소스 클러스터로부터 데이터(토픽)를 읽어와서 타겟 클러스터에 복제해요.
작업 구성요소 (Job Components)
데이터 미러링 작업을 구성하는 커넥터들을 뜻해요. 데이터 미러링에서 사용되는 구성요소의 종류는 다음과 같아요.
- 데이터 복제(MirrorSourceConnector) : 소스 클러스터에서 데이터를 읽어서 타겟 클러스터로 복제하는 역할을 해요. Sync 커넥터와 Source 커넥터가 결합된 형태에요.
- 컨슈머 오프셋 동기화(MirrorCheckpointConnector) : 소스 클러스터와 타겟 클러스터 간 컨슈머 그룹의 오프셋을 동기화해요. 이를 통해, 클러스터 장애 시, 컨슈머들이 올바른 위치에서 다시 데이터를 처리하도록 도울 수 있어요.